Overview
Motivating Example
A robot working alongside people must reason about what they have done, in what order, and with what intent. Here's an example. The robot watches a person rearrange objects. It's then given an instruction: put the moved objects back where they were. It then executes the plan in a digital twin of the scene. To succeed, the robot must reason from the human video and plan its next actions — a setting overlooked by prior work.
Instruction: “Put the moved objects back where they were.”
WatchAct Instances
Language Instruction: “Put the object that was shaken vigorously into the basket farther from the camera.”

Language Instruction: “Put the displaced boxes back in their original positions.”

Language Instruction: “Move objects by imitating human action sequences.”

Language Instruction: “Put the object that was picked up three times into the tray.”

Language Instruction: “Put the displaced boxes back in their original positions.”

Spatial Reasoning Design
- Videos are captured from diverse camera viewpoints.

Frontal View 
Side View 
Oblique View 
Frontal View 
Side View 
Oblique View 
Frontal View 
Side View 
Oblique View - Language instructions use varied reference frames, either human-centered or camera-centered:
- Human-centered: e.g., "the cup on the human's left"
- Camera-centered: e.g., "the cup on the camera's left"
Experimental Takeaways
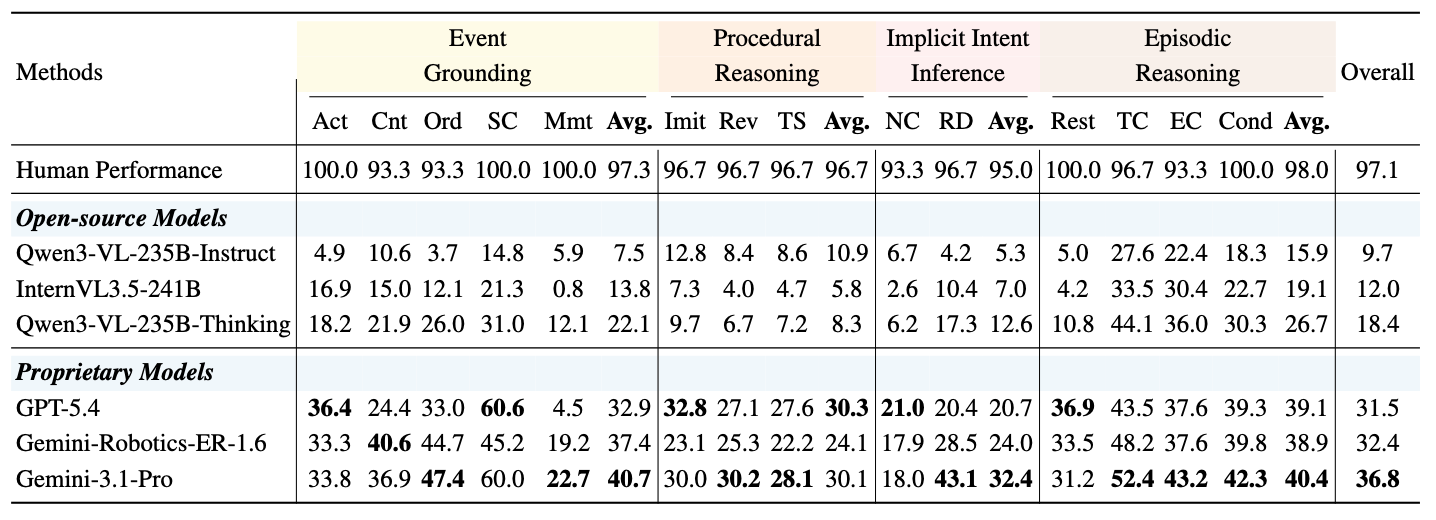
Takeaway 1: VLMs struggle with video-to-plan reasoning.
The best model, Gemini-3.1-Pro, reaches only 36.8%, a gap of 60.3 points, which indicates that inferring a valid manipulation plan from video remains a major challenge for current VLMs.
Takeaway 2: Robotic policies struggle to follow oracle plans.
Even with oracle plans, current policies struggle on WatchAct.
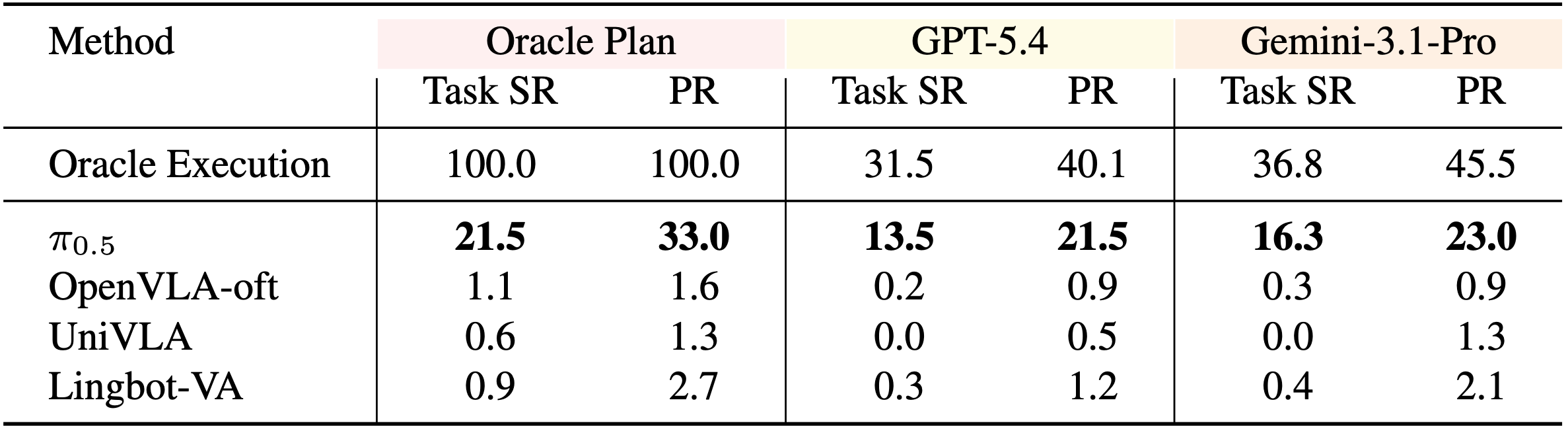
Takeaway 3: Errors accumulate across the integrated pipeline.
Predicted plans degrade execution relative to oracle plans. Paired with π0.5, Gemini-3.1-Pro plans reach 16.3% Task SR and GPT-5.4 plans 13.5%, both below the 21.5% oracle-plan ceiling.
Rollout Demos
We show several rollout demos from LIBERO simulation and real-world experiments.
BibTeX