
Hello! I’m Baiqi Li, a first-year PhD student in Computer Science at the University of North Carolina at Chapel Hill, advised by Gedas Bertasius. My research interests focus on video-related topics and their applications in robotics. Before joining UNC, I had the privilege of conducting research with Deva Ramanan. I gruduated from East China Normal University in Shanghai, China.
🔥 News
- 2024.09: 🎉🎉 Our paper NaturalBench: Evaluating Vision-Language Models on Natural Adversarial Samples was accepted by NeurIPS2024.
- 2024.08: 🎉🎉 Our VQAScore was rated by Imagen as the strongest text-to-vision evaluation metric, and our benchmark, GenAI-Bench, was also extensively used by Imagen.
- 2024.06: 🎉🎉 Our workshop paper GenAI-Bench: A Holistic Benchmark for Compositional Text-to-Visual Generation has been selected as the best paper at SynData4CV workshop @ CVPR2024.
- 2024.06: We introduced GenAI-Bench for evaluating the performance of leading image and video generation models in various aspects of compositional text-to-visual generation and evaluation metrics.: GenAI-Bench: Evaluating and Improving Compositional Text-to-Visual Generation.
- 2024.06: We proposed a semi-automated approach to collect a vision-centric benchmark, NaturalBench, for reliably evaluating VLMs: NaturalBench: Evaluating Vision-Language Models on Natural Adversarial Samples.
- 2024.04: We introduced VQAScore for evaluating the prompt alignment of text-to-image/video/3D models: Evaluating Text-to-Visual Generation with Image-to-Text Generation.
📝 Publications

NaturalBench: Evaluating Vision-Language Models on Natural Adversarial Samples
Baiqi Li*, Zhiqiu Lin*, Wenxuan Peng*, Jean de Dieu Nyandwi*, Daniel Jiang, Zixian Ma, Simran Khanuja, Ranjay Krishna †, Graham Neubig †, Deva Ramanan †
Website | Arxiv | HuggingFace |

- In this work, we show that VLMs still struggle with natural images and questions that humans can easily answer, which we term natural adversarial samples.
- We propose a semi-automated approach to collect a new benchmark, NaturalBench, for reliably evaluating VLMs with over 10,000 human-verified VQA samples.
- Evaluated NaturalBench on 53 vision-language models, including both open-source and closed-source examples like GPT4-o, Qwen2-VL, Molmo, and InternVL
- Mitigating biases, such as the tendency of GPT-4o to agree with most questions due to lack of calibration, can yield a 100\% improvement in model performance.
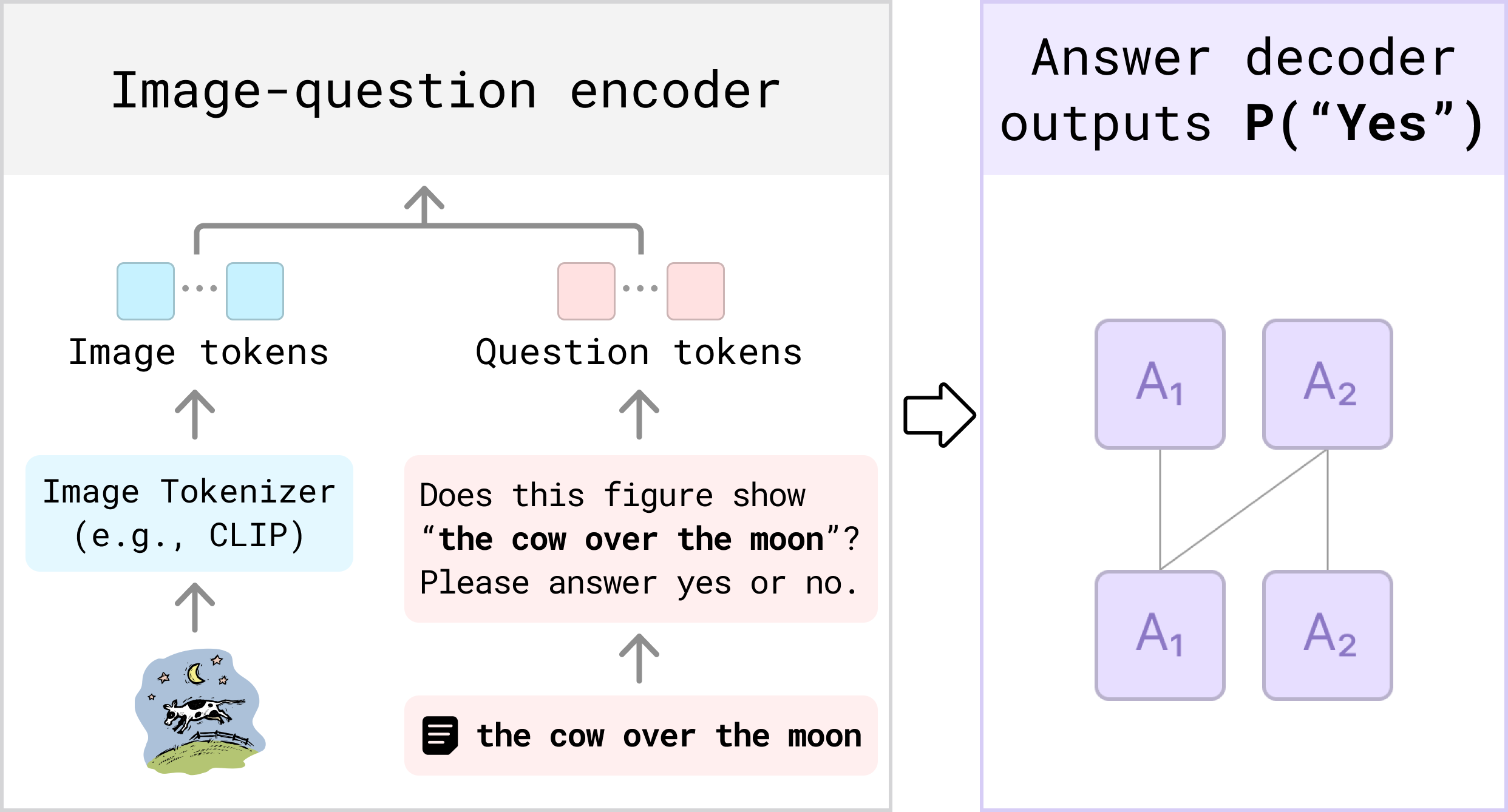
Evaluating Text-to-Visual Generation with Image-to-Text Generation
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Emily Li, Xide Xia, Graham Neubig, Pengchuan Zhang †, Deva Ramanan †

- We propose VQAScore, the state-of-the-art alignment metric for text-to-image/video/3D models.
- VQAScore based on our new CLIP-FlanT5 model outperforms previous metrics based on GPT-4Vision or costly human feedback.
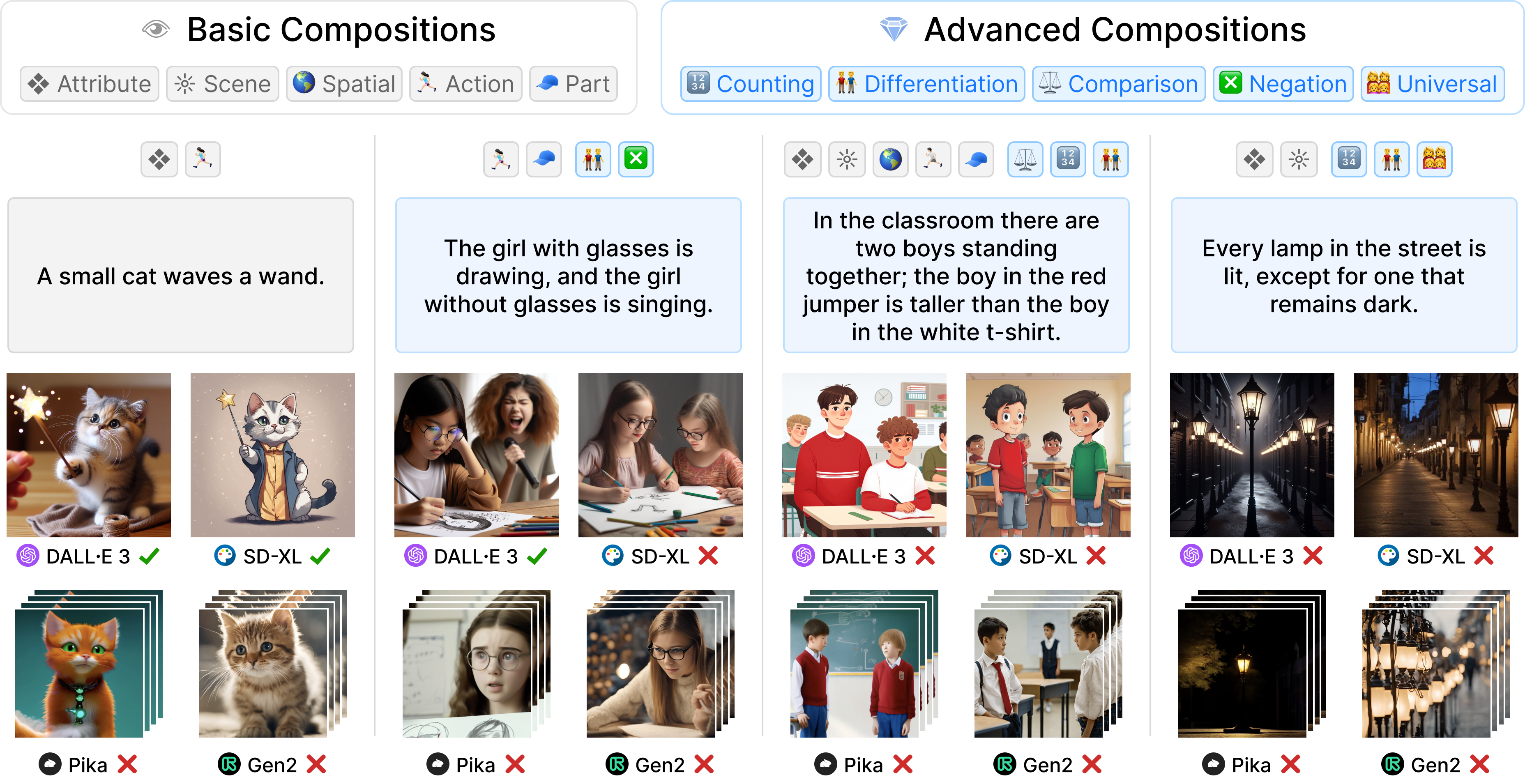
GenAI-Bench: Evaluating and Improving Compositional Text-to-Visual Generation
Baiqi Li*, Zhiqiu Lin*, Deepak Pathak, Emily Li, Feiyi Xin, Kewen Wu, Tiffany Ling, Xide Xia †, Pengchuan Zhang †, Graham Neubig †, Deva Ramanan †
Website | Arxiv | HuggingFace
- We conduct an extensive human study on compositional text-to-visual generation using GenAI-Bench, revealing limitations of leading open-source and closed-source models.
- We present a simple black-box approach that improves generation by ranking images with VQAScore, significantly surpassing other scoring methods by 2x to 3x.
- We will release GenAI-Rank with over 40,000 human ratings to benchmark methods that rank images generated from the same prompt.
🎖 Honors and Services
- Reviewer: Neurips, ICLR, ECAI, TIST …
📖 Research Experience
- 2025.08 - present, PhD, University of North Carolina at Chapel Hill.
- 2024.01 - 2025.06, Research Assistant, Carnegie Mellon University.